ALGORITHMS
What is Perceptron in Algorithms?
In machine learning, the perceptron is an algorithm for supervised learning of binary classifiers.
- Read time
- 6 min read
- Word count
- 1,357 words
- Date
- May 17, 2020
🌟 Non-members read here
A binary classifier is a function that has the potential to determine whether an input, portrayed by a vector of numbers, could be a part of some given class. It can be considered as a type of linear classifier. This is often defined as a classification of algorithms which has the capability of predicting based on linear predictor function, together with a set of weights along with a feature vector.
In the field of machine learning, an algorithm utilized for supervised learning of binary classifiers is entitled as a perceptron.
Definition
In recent times, the perceptron is used as an algorithm for learning binary classifiers — known as threshold function. A threshold function is a function that matches its input x, a real-valued vector, with an output value f(x), a single binary value.
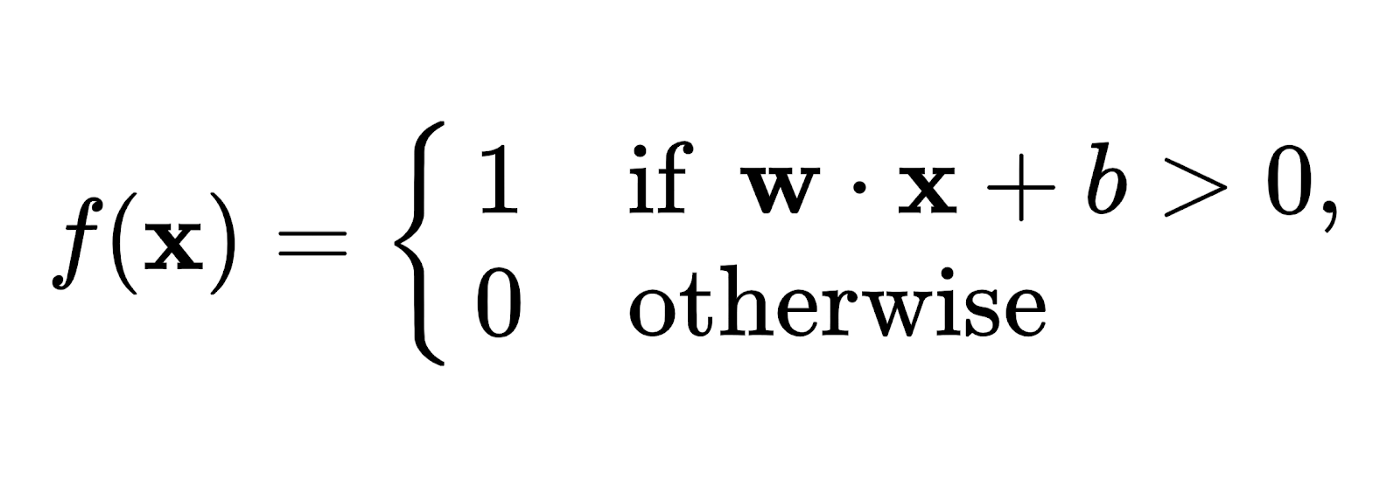
In the above equation, w · x is the summation of all values of the dot product such that i=1, 2, …, m for wᵢxᵢ. Here, m is the count of inputs, and b is the bias. The value of b can shift the boundary of decisions away from the origin.
| Note that the value of this f(x) (which can either be 0 or 1) is utilized to segregate into either a positive or a negative instance, when it comes to problems related to binary classification. When b is negative — the weighted combination of inputs then produces a positive value, which is higher than the absolute value of ‘b’ — **_ | b | _** in order to shift the classifier neuron over the 0 threshold. Furthermore, the bias changes the position (not specifically the orientation) of the decision boundary. Termination does not occur in perceptron learning algorithms when the learning set is linearly inseparable in nature. In case the vectors are separable linearly, then the learning does not reach a situation where the vectors are properly classified. A popular example of the perceptron’s incapability to find solutions to problems pertaining to linearly non-separable vectors can be observed within the Boolean exclusive-or problem. |
In the field of neural networks, perceptrons are artificial neurons that utilize the Heaviside step function as their activation function. The perceptron algorithm is sometimes called a single-layer perceptron, so as to differentiate it from the multilayer perceptron — an opposing term for complex neural networks. The single-layer perceptron is the simplest form of feedforward neural network, being linearly classified.
Convergence
Now that we have understood that the perceptron is a linear classifier, hence it will almost never reach a phase when all the input vectors are correctly classified, in cases where the training set D is non-linearly separable. This is the case when positive examples are inseparable from the negative examples using a hyperplane. Thus, no approximate solution can be obtained using the standard learning algorithms, rather the learning fails. Therefore, if linear separability is unknown, then one of the following training variants of the training set can be exploited.
In case the training set is linearly separable, the perceptron is sure to converge, along with an upper bound on the number of times the perceptron will accommodate its weights during the training session.
Although this perceptron algorithm should converge on a given solution when it comes to a linearly separable training set, it may still be possible that any solution can be picked, while the problems may allow multiple solutions of different levels of quality. Better known as a linear support vector machine, the perceptron of optimal stability was designed to mitigate this issue.
Variants
The pocket algorithm with ratchet is used to solve the stability problem of perceptron learning by locking the most optimum observed solution within its pocket. This pocket algorithm then returns the solution within the pocket, rather than the previous solution. It may also be used for non-separable sets of data, in cases where the objective is to look for a perceptron with little number of misclassifications. However, these solutions purely appear stochastically and therefore, in these cases, the pocket algorithm neither approaches them gradually in the journey of learning, nor are they guaranteed to appear within a given number of learning steps.
The Maxover algorithm is quite robust such that it converges regardless of previous knowledge of linear separability of the data set. In the case of a linearly separable data set, it solves the training problem — if required, even with optimal stability (i.e. maximum margin in between the classes). However, for non-separable data sets, it returns a solution with little misclassification. In each case, the algorithm eventually reaches the solution through the course of learning, neither by memorizing earlier states nor through stochastic leaps. The convergence is mainly towards global optimality for data sets that are separable and to local optimality for non-separable sets of data.
The Voted Perceptron is a kind of a variant using numerous weighted perceptrons. The algorithm usually begins with a new perceptron every time an example is mistakenly categorized, initializing the weights vector with final weights of the previous perceptron. Each perceptron is given an alternative weight corresponding to the number of examples they categorized correctly, prior to mistakenly classifying one, and in the end the output will be equivalent to the weighted vote over all the perceptrons.
In distinguishable problems, perceptron training can be used to find the largest separation of margin between the different classes. In this case, the perceptron of optimal stability can be obtained through iterative training and optimization schemes, like the Min-Over algorithm or the AdaTron. Note that the AdaTron assumes that the corresponding quadratic optimization problem is convex in nature. As such, the perceptron of optimal stability, along with kernel trick, are the concept-level foundations of support vector machines.
The α-perceptron also uses a pre-processing layer of random weights which are fixed, having output units with thresholds. This empowered the perceptron to segregate analog patterns, by placing them within a binary space. Note that for an adequately high dimensioned projection space, patterns can convert into linearly separable.
An alternate way of solving nonlinear problems without the use of multiple layers, is the use of higher order networks (such as the sigma-pi unit). In such a type of network, each element within the input vector, along with every pairwise combination of multiplied second order inputs, is extended. Therefore, this condition can also be extended to an n-order network.
However, it’s important to note that the best of the classifiers is not mandatorily the one that segregates all training data in the perfect manner. Undoubtedly if we had a previous constraint that the data was obtained from equi-variant Gaussian distributions, the linear separation within the input space would be optimal, and the nonlinear solution is observed to be overfitted. Alternative linear classification algorithms include Winnow, logistic regression, and support vector machines.
Multiclass Perceptron
Similar to the majority of the other techniques used for training linear classifiers, the perceptron simplifies naturally to multiclass categorization. In this case, the input and output (x and y respectively) are obtained from arbitrary sets. Hence, a feature representation function — f(x, y) maps each probable pair of input and output to a finite-dimensional real-valued feature vector. Just like before, a feature vector is multiplied by a weight vector denoted by w, but the resulting score is now used to select from within multiple possible outputs:
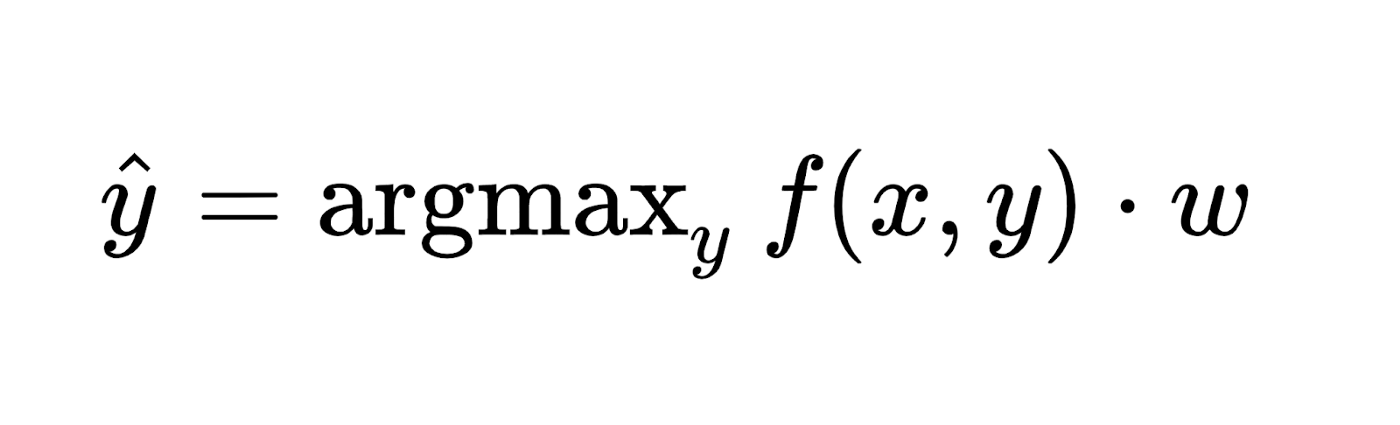
The learning process again iterates over all the examples, predicting for each output, while leaving the weights unaltered when the predicted output matches the target, alternatively changing them when it does not match. Therefore, the update turns into:
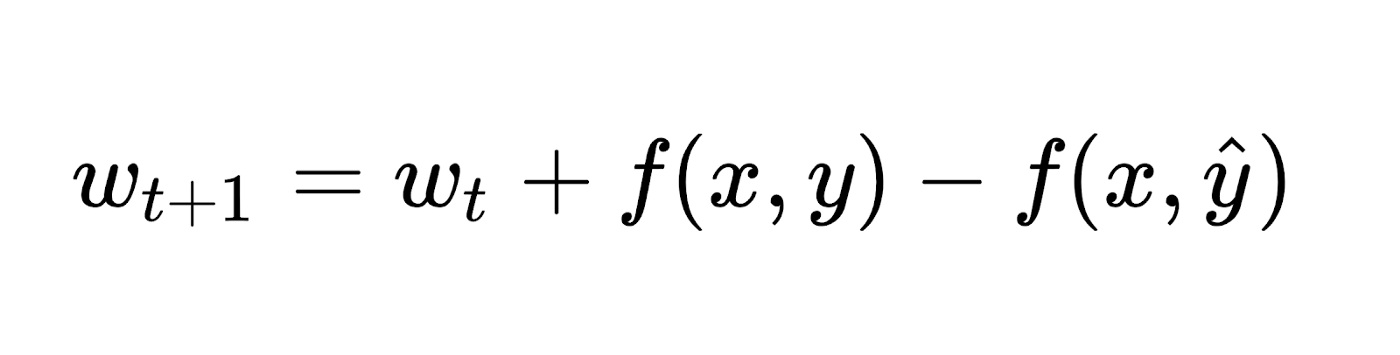
The multiclass feedback formulation minimizes to the original perceptron when:
x is a real-valued vector
y chosen from {0, 1}, and
f(x, y) = yx
In case of specific problems, the input-output features and indications can be opted in such a way that argmaxᵧ f(x, y) · w can be efficiently obtained, even though y comes from even an infinite set.
Conclusion
Since the year of 2002, perceptron training has gained a lot of popularity in the natural language processing domain for similar tasks as a part-of-speech tagging and syntactic parsing. It can be applied to large-scale machine learning problems in a distributed computing set up.